Generative UI
December 18, 2024
Before we dive into generative UI, let's explore some key challenges in AI applications.
Currently, ChatGPT assists users by providing plain text and markdown responses. However, this approach has limitations the knowledge is constrained and not always accurate.
If you see the above image the model doesn't have access to external APIs or tools so it cannot provide you with the real-time data. Their training data is limited and they may not always have the most up-to-date information.
Tools and function calling
Understanding Tools
Tools are specialized functions that enable AI models to interact with external systems and perform specific tasks. They extend the model's capabilities beyond its training data, allowing it to:
- Access real-time information
- Interact with APIs and databases
- Perform calculations
- Execute specific operations
Example: Flight Search Tool
For instance, when a user asks about available flights, the model recognizes it needs current flight data. Instead of relying on its potentially outdated training data, it:
- Identifies the need for flight information
- Calls the
searchFlightstool - Receives real-time flight data from external APIs
- Processes the data and presents it to the user
This approach ensures that users receive accurate, up-to-date information rather than potentially outdated training data.
With the introduction of tools and function calling in the LLM models (like GPT-4 and Claude 3.5) we can interact with external tools and APIs.
The diagram shows the flow of a typical AI application that can fetch real-time data. Here's how they work:
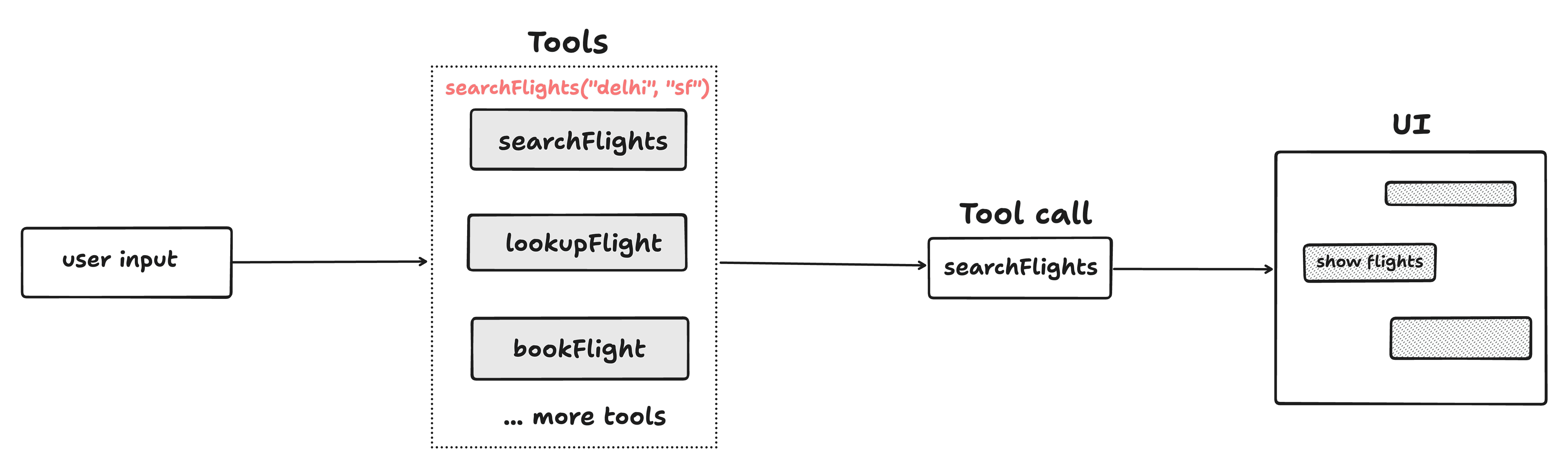
- User sends a prompt to the language model
- Model selects the appropriate tool from available functions
- Model calls the selected function with parameters
- Tool returns real-time data for processing
- Model generates a natural language response to the user
Let's look at how we can implement the approach in our frontend code.
function ChatInterface() {
return (
<div>
{messages.map((message, index) => (
<div
key={index}
className={message.role= "assistant" ? "assistant" : "user"}
>
{message.content}
</div>
))}
</div>
);
}
This example shows how Tools and Function Calling allow AI to interact with external data sources and provide up to date information to users.
We have now solved one of the problems by providing more knowledge to the LLMs.
Next, we will see the rendering of the user interface using language models.
Rendering user interfaces with language models
We can improve the user experience by having the model return structured JSON data instead of plain text. This allows us to represent flight information in a more organized way.
The JSON response can then be used to render a React component like this:
return (
<div>
{messages.map(message => {
if (message.role === "tool") {
const { name, content } = message;
const { arrivalCity, departingCity, date } = content;
return (
<ListFlights
flights={{
arrivalCity,
departingCity,
date
}}
/>
);
}
})}
</div>
);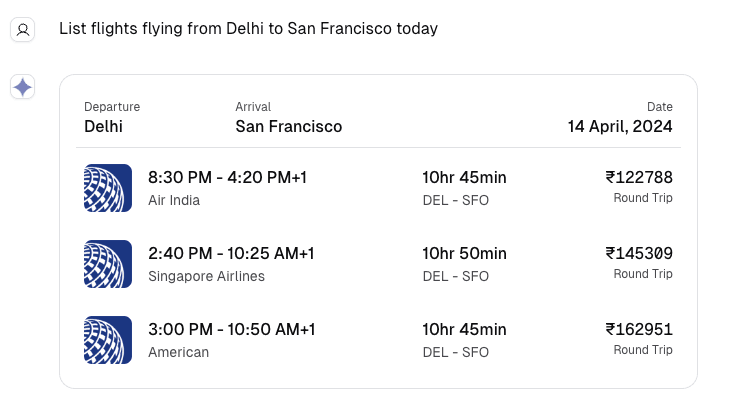
By rendering a proper ListFlights component instead of plain text, we have improved the application's user experience. This approach enables users to interact with language models in a more visual and interactive way.
We have now solved another key challenge by successfully integrating UI rendering with language models.
Rendering multiple user interfaces
When building an AI assistant capable of handling multiple user scenarios, we need to render different user interfaces based on the specific user query.
{
message.role === "tool" ? (
message.name === "api-list-flights" ? (
<ListFlights flights={message.content} />
) : message.name === "api-search-courses" ? (
<Courses courses={message.content} />
) : message.name === "api-meetings" ? (
<Meetings meetings={message.content} />
) : message.name === "api-events" ? (
<Events events={message.content} />
) : null
) : (
<div>{message.content}</div>
);
}This code shows multiple tools that can be called by the language model, each returning a different user interface component. We use conditional rendering to determine which component to display based on the tool name.
However, as this list of tools grows the complexity of our application increases significantly. Managing these different user interfaces can become challenging, especially when we need to add new tools or modify existing ones. This approach will work but might not scale well for larger applications.
Rendering user interfaces on the server
Thanks to React server components (RSC), server functions and the new suspense SSR architecture, we can now handle UI rendering more efficiently. React introduced RSCs back in 2022, and it was released in React 19.
RSCs solve the problem of managing components on the client side by allowing us to render them on the server and stream them to the client. Instead of conditionally rendering user interfaces on the client based on the language model's output, we can directly stream them from the server during model generation.
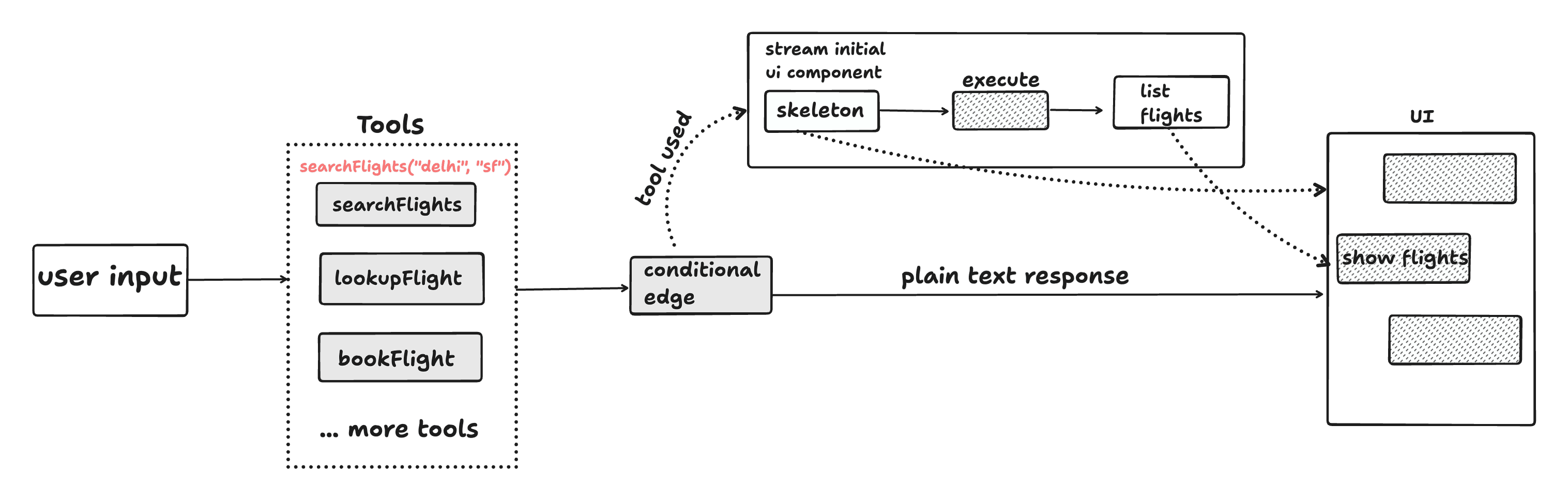
Let's understand how this works:
- The user sends a prompt to the language model
- These tools are bound to the LLM
- Conditional edges differentiate between deterministic and probabilistic outcomes
The challenge of non-deterministic UIs
Generative UIs aren't deterministic because they depend on the model's generation output. Since these generations are probabilistic, it's possible for every user query to result in a different user interface. This is problematic because users expect their experience to be predictable making non-deterministic user interfaces a less than ideal solution.
However, there is a solution for this. We can guide these language models by setting them up to use specific functions, putting boundaries on what they generate. This ensures their outputs stick to a particular set of options we define "like giving the AI a menu to choose from".
When we provide language models with function definitions and instruct them to execute based on the user query, they will:
- Execute the function that is most relevant to the user query
- Not execute any function if the user query is out of bounds
This approach ensures that the generations result in deterministic outputs, while the model's choice remains probabilistic. The combination allows language models to reason about which function to execute and render appropriate user interfaces.
The response is then streamed directly to the client and rendered in real-time.
import { createStreamableUI } from "ai/rsc";
const uiStream = createStreamableUI();
const text = generateText({
model: openai("gpt-4"),
system:
"You are a friendly assistant that helps the user with booking flights...",
prompt: "List flights flying from Delhi to San Francisco today",
tools: {
showFlights: {
description:
"List available flights in the UI. List 3 that match user's query.",
parameters: {},
execute: async ({ arrivalCity, departingCity, date }) => {
const flights = getFlights({ arrivalCity, departingCity, date });
const { price, time, arrivalAirport, departingAirport } = flights;
uiStream.update(<CardSkeleton />);
uiStream.done(
<ListFlights
flights={{
arrivalCity,
departingCity,
date,
price,
time,
arrivalAirport,
departingAirport
}}
/>
);
}
}
}
});
return {
display: uiStream.value
};
// On the client side, we only need to
// render the UI that is streamed from the server.
return (
<div>
{messages.map(message => (
<div>{message.display}</div>
))}
</div>
);The future of Generative UI
Apps like Perplexity is already utilizing generative UI technology to render custom UIs based on user-specific information:
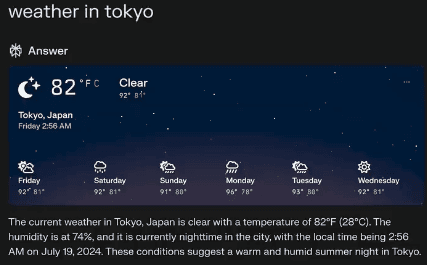
On the other hand, the Vercel team has created an app called v0 that generates UI from simple text prompts:
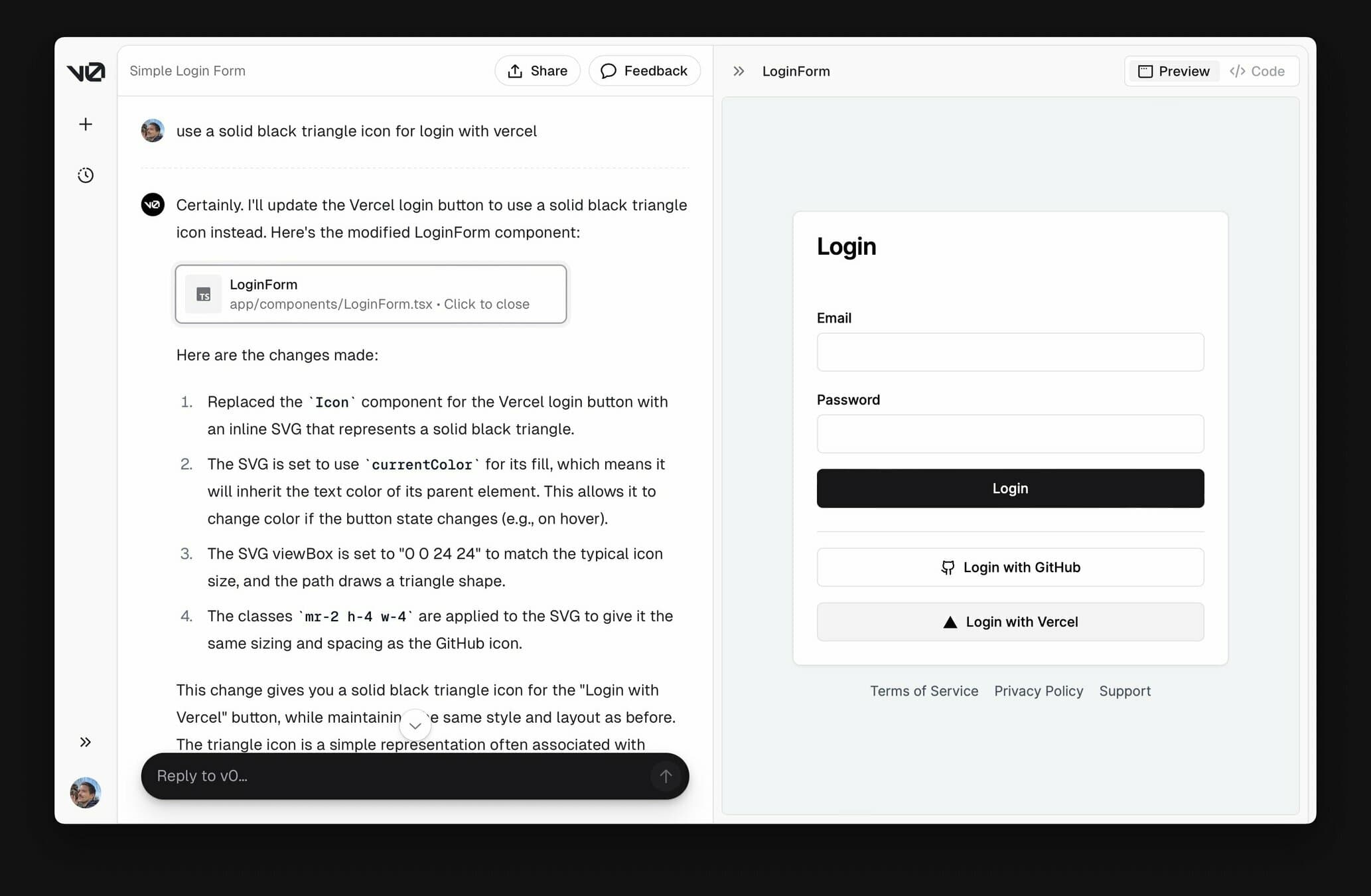
As language models become better at reasoning, so we can assume that there is a future where we only write core application like the UI components while models take care of routing them based on the user's state.
With generative UI, the language model decides which user interface to render based on the user's state in the application. This gives users the flexibility to interact with the application in a conversational manner instead of navigating through predefined routes.
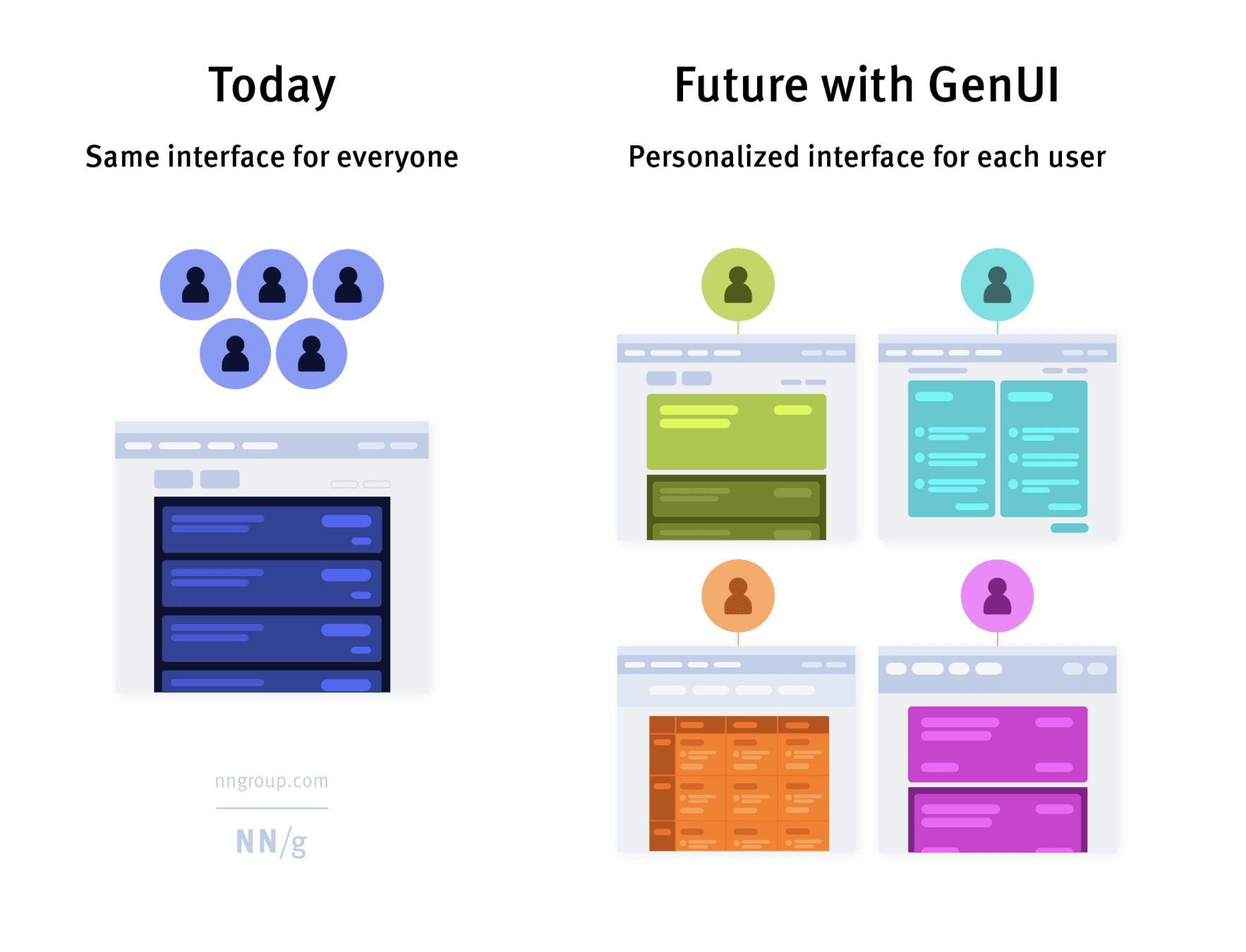
Image source: https://www.nngroup.com/articles/generative-ui/
The future with generative UI looks like that we build our own design system and pass it to language models. These models will be smart enough to compose components, stitch pieces together, and create dynamic pages that adapt to each user's needs.
Update
Since this post was drafted in July 2024, there has been a lot of progress in the GenAI space. A few of the notable changes are:
- ChatGPT Search: This is a new feature that allows ChatGPT to search the web for information. If I ask the same question as above, it will now return a list of flights.
